EvoCode-Bench
Opus-4.8: 59.1 Dataset Score · Coding
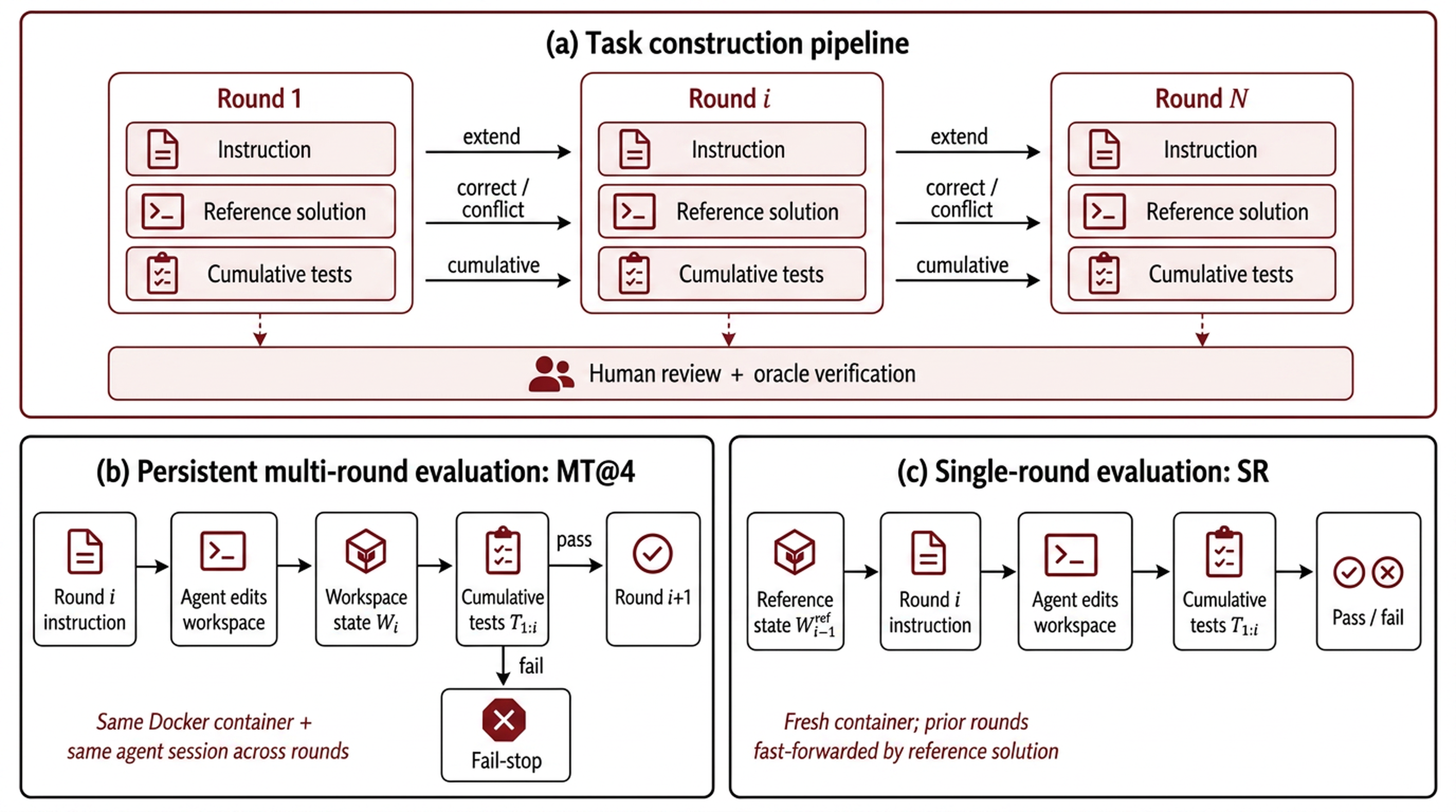
EvoCode-Bench tests whether coding agents can keep a project working as user requests change. It evaluates agents on 26 stateful coding tasks and 227 rounds, with the same workspace and agent session preserved for 5-15 rounds.
Leaderboard
The current leaderboard is the 2026-06-25 update to the clean re-release, evaluated under the Harbor official multi-step format with one attempt per task. The main ranking mode is Dataset Score: each round is verified independently with a binary reward, each task scores passed_rounds / total_rounds, and the final score is the mean across the 26 tasks. Per-round, per-test-case detail for every task is available on the interactive results site. The clean evaluation trajectories are released with the Hugging Face dataset; each reached benchmark round includes an agent/trajectory.json file for auditing model behavior and Avg Rounds.
| # | Agent | Dataset Score | Case Score | Avg Rounds | Perfect Tasks | Reasoning |
|---|
- Dataset Score is the headline score on a 0–100 scale. For each task, compute
passed_rounds / total_rounds, then average that task score over all 26 tasks and multiply by 100. A round earns 1 only if every required test case passes; if the chain aborts before later rounds, those unreached rounds count as 0. This is similar in spirit to MT@1 because it is one attempt per task, but it is not the legacy paper MT@1: this table uses Harbor official multi-step full-chain runs and averages binary per-round rewards within each task first. - Case Score is the finer-grained companion on a 0–100 scale. For each round, compute
passed_test_cases / total_test_cases; build failures and unreached rounds count as 0. Then average over the task's rounds and over the 26 tasks. It credits partial progress that Dataset Score hides; GPT-5.5, for example, scores 29.5 on binary round rewards but 81.8 on test cases. - Avg Rounds is the mean number of agent-tool interactions per reached benchmark round, computed from each reached round's
agent/trajectory.json. It is not the number of benchmark rounds in a task. If a chain stops early, missing later benchmark rounds are not included in this average, while they still count as 0 for Dataset Score and Case Score. - Perfect Tasks counts tasks where every benchmark round passed. A value of
9 / 26means 9 full tasks were completed end to end, or 34.6% full-task completion.
A note on evaluation integrity (results updated 2026-06-25). While auditing trajectories from our first run we found a Harbor framework issue: in the default shared multi-step mode, the previous round's grading script (/tests/test.sh) and reward persist into the next round's agent workspace, so an agent can read the grader from inside its own run. We observed this on 12 of 26 tasks (22 task–model pairs), concentrated in a few models. We reported it upstream (issue #1960, fix PR #1961), patched our harness, and re-ran the whole benchmark clean — the numbers above are from the patched runs and replace the leaderboard published June 13–16. Earlier v1 numbers are historical only and are not shown in the current leaderboard. Per-(task, model, round) detail and the full changelog are in the GitHub repo.
How It Works
Each task is a sequence of user rounds run in one persistent Docker container with one continuous agent session. At round i, the agent receives a new instruction, edits the same workspace, and is verified by a cumulative test suite covering all still-active requirements through round i. Every round runs and is scored with a binary 0/1 reward; the chain does not short-circuit, and the trial score is the mean of the per-round rewards. Because every round is scored independently, the per-round pattern is itself diagnostic of which requirements an agent can and cannot satisfy.
Evaluation Scaffold
EvoCode-Bench runs on the Harbor official multi-step format — the same framework used by Terminal-Bench 2.0 — using its native [[steps]] sequencing, a single persistent workspace, a per-step verifier, and multi_step_reward_strategy = "mean" aggregation. No fork is required to run a full task. Single-round fast-forward (solving a target round from a reference-completed prior state) is provided by our fork harbor-official-fast-forward.
harbor run <task> --agent oracle | nop | <model>. The oracle reference solutions score 1.0 on every round; empty submissions score 0. See github.com/UniPat-AI/EvoCodeBench for the evaluation scripts and leaderboard recomputation command.
harbor_multiturn fork with the MT@4 / SR / Comp metrics (best-of-four, fail-stop). Those numbers use a different runner and a different scoring rule than the official multi-step dataset score above and are not directly comparable. They are kept here for reproducibility of the paper.
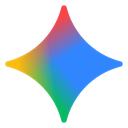
Leaderboard (Legacy · MT@4)
The main score is MT@4: a best-of-four fail-stop multi-round score. A round receives credit only if at least one attempt reaches that round with a workspace that still satisfies all active cumulative tests.








Full Results (Legacy · MT@4)
| # | Agent | MT@4 | SR | Gap | Comp | Avg Turns | Output Tok. |
|---|---|---|---|---|---|---|---|
| 1 | Claude-Opus-4.7-High Anthropic high reasoning effort | 54.0 | 76.7 | +22.7 | 42.3 | 590.6 | 50.0K |
| 2 | GPT-5.5-High OpenAI high reasoning effort | 52.4 | 74.4 | +22.0 | 38.5 | 456.3 | 74.1K |
| 3 | Claude-Opus-4.6 Anthropic default configured reasoning | 44.0 | 78.9 | +34.9 | 34.6 | 747.5 | 734.2K |
| 4 | GLM-5.1 Zhipu AI thinking enabled | 36.2 | 63.9 | +27.7 | 15.4 | 859.8 | 104.2K |
| 5 | Kimi-K2.6 Moonshot AI thinking enabled | 31.9 | 59.0 | +27.1 | 23.1 | 1155.5 | 92.5K |
| 6 | DeepSeek-V4-Pro DeepSeek high reasoning effort | 30.6 | 56.4 | +25.8 | 19.2 | 1134.8 | 168.8K |
| 7 | Qwen3.6-Plus Alibaba thinking enabled | 29.4 | 57.3 | +27.9 | 15.4 | 629.3 | 103.1K |
| 8 | Xiaomi-MiMo-V2.5-Pro Xiaomi high reasoning effort | 17.3 | 7.9 | -9.4 | 11.5 | 754.8 | 125.7K |
| 9 | Gemini-3.1-Pro-Preview Google high reasoning effort | 13.7 | 46.7 | +33.0 | 11.5 | 261.3 | 72.7K |
| 10 | DeepSeek-V4-Flash DeepSeek high reasoning effort | 9.4 | 46.3 | +36.9 | 0.0 | 1104.7 | 148.7K |
| 11 | Qwen3.5-397B-A17B Alibaba thinking enabled | 4.6 | 44.1 | +39.5 | 0.0 | 587.8 | 53.0K |
| 12 | MiniMax-M2.7 MiniMax reasoning split enabled | 3.7 | 30.0 | +26.3 | 0.0 | 600.4 | 59.2K |
| 13 | Doubao-Seed-2.0-Pro ByteDance high reasoning effort | 1.9 | 23.8 | +21.9 | 0.0 | 211.1 | 18.5K |
How It Works (Legacy · MT@4)
Each task is a sequence of user rounds. At round i, the agent receives a new instruction, edits the same Docker workspace, and is evaluated by cumulative tests for all still-active requirements through round i. If the cumulative verifier fails, the multi-turn attempt stops and later rounds receive zero credit.
Evaluation Scaffold (Legacy · harbor_multiturn)
The paper evaluation used harbor_multiturn, the multi-turn Harbor fork released at github.com/UniPat-AI/harbor_multiturn. The scaffold adds persistent Docker workspaces, continuous agent sessions, round-boundary verifier swaps, reference fast-forwarding for SR, snapshot/resume lineage, and fail-stop reward aggregation.
harbor_multiturn handles that protocol: it delivers each round instruction, preserves the workspace, swaps in cumulative tests for the current round, records verifier/multiround_results.json, and writes the aggregate reward used by MT@4.
Dataset Overview
The paper groups EvoCode-Bench tasks along two axes: interaction style, or how users communicate across rounds, and engineering activity, or what kind of code change the round asks for. Each cell reports tasks / rounds.
| Activity | Capability Measured | Explorative | Contractual | Document-Driven | Total |
|---|---|---|---|---|---|
| Construction | Building a system incrementally while preserving earlier features and interfaces. | 9 / 80 | 3 / 37 | 1 / 7 | 13 / 124 |
| Spec Evolution | Updating an implementation after a later round overturns a core assumption. | 1 / 8 | 1 / 7 | 1 / 7 | 3 / 22 |
| Review | Improving non-functional properties such as performance, security, and observability without regression. | 3 / 21 | 1 / 7 | 1 / 9 | 5 / 37 |
| Migration | Moving a legacy system to a new implementation style while keeping backward compatibility. | 3 / 29 | 1 / 7 | 1 / 8 | 5 / 44 |
| Total | 16 / 138 | 6 / 58 | 4 / 31 | 26 / 227 |
Analysis (Legacy · Paper)
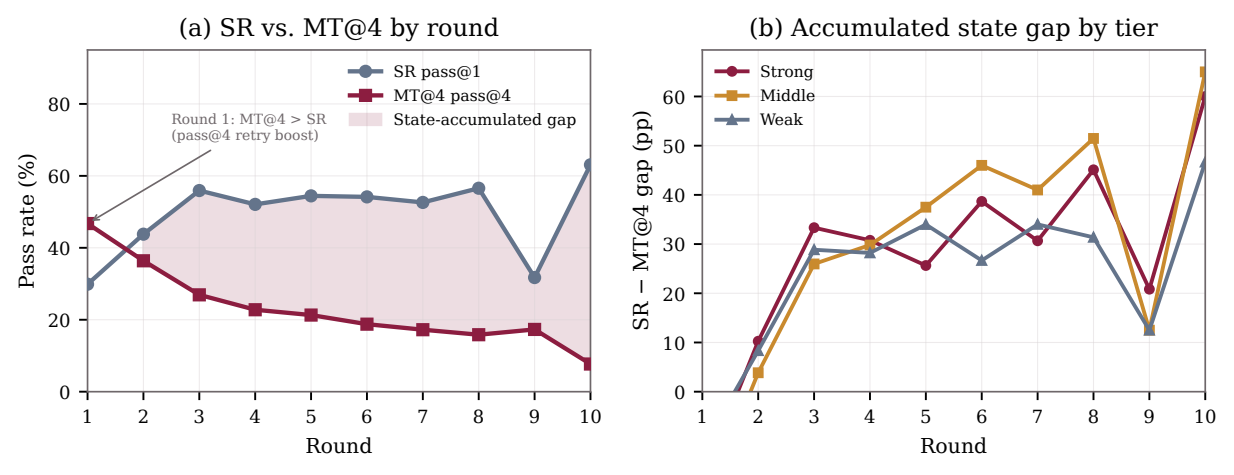
Single-Round Skill Does Not Imply Persistent Reliability
SR exceeds MT@4 by 22 to 40 points for most agents. Claude-Opus-4.6 has the highest SR at 78.9, but ranks third on persistent execution at 44.0 MT@4. The reranking shows that solving an isolated round from a clean reference state is different from living with one's own earlier edits.
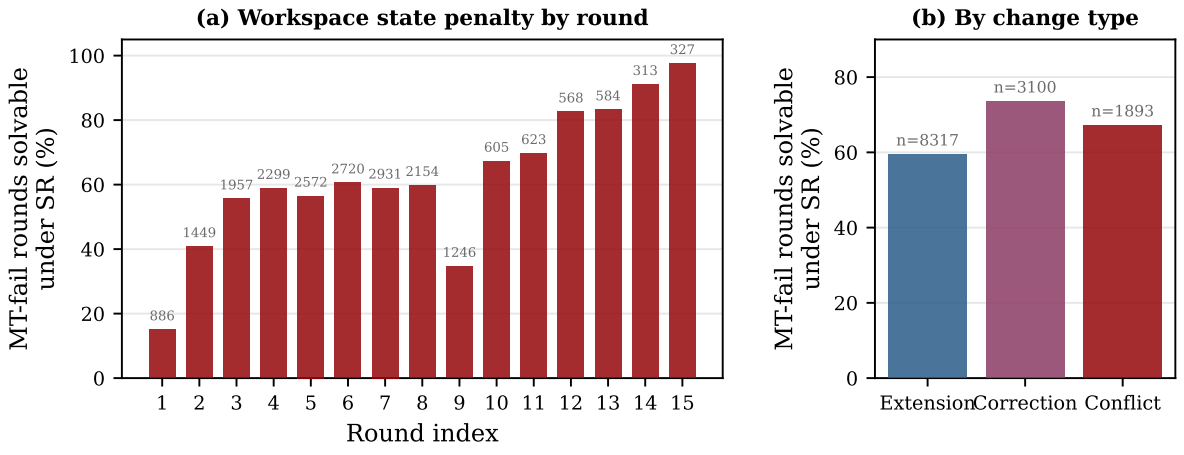
Workspace State Drives a Large Share of Failures
A controlled comparison shows that 57.0% of failed MT@4 round records are solvable under SR from a reference-completed state. The state penalty grows with depth: only 15.0% of round-1 MT failures are SR-solvable, rising above 80% beyond round 12.
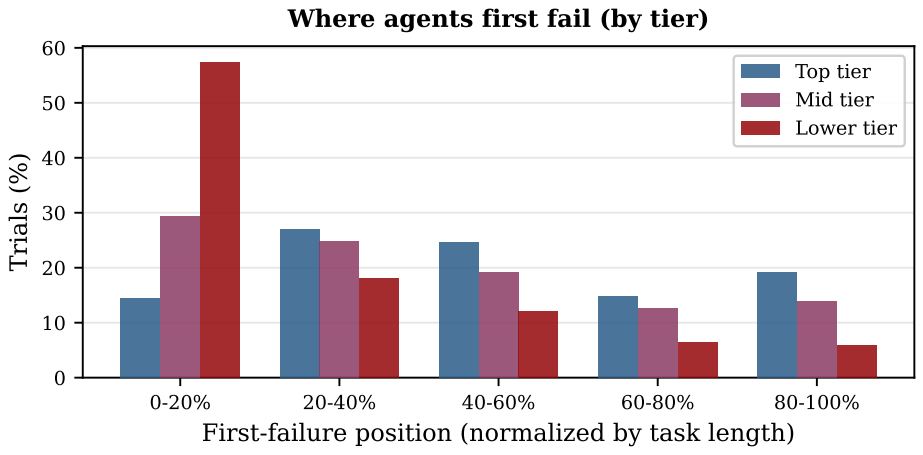
Failure Patterns Are Tier-Dependent
Missed active requirements dominate every tier, but the secondary modes differ. Lower-tier agents fail early: 57.4% of lower-tier trial failures occur in the first 20% of rounds. Stronger agents survive long enough for stale behavior, regressions, and conflict-resolution errors to appear.
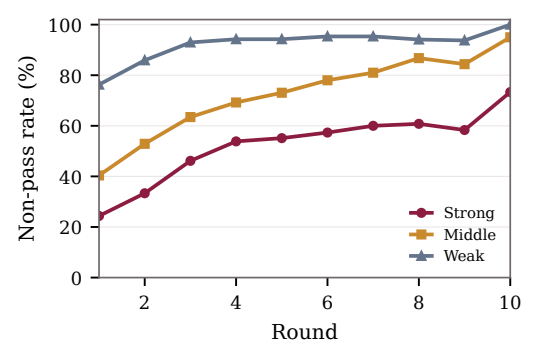
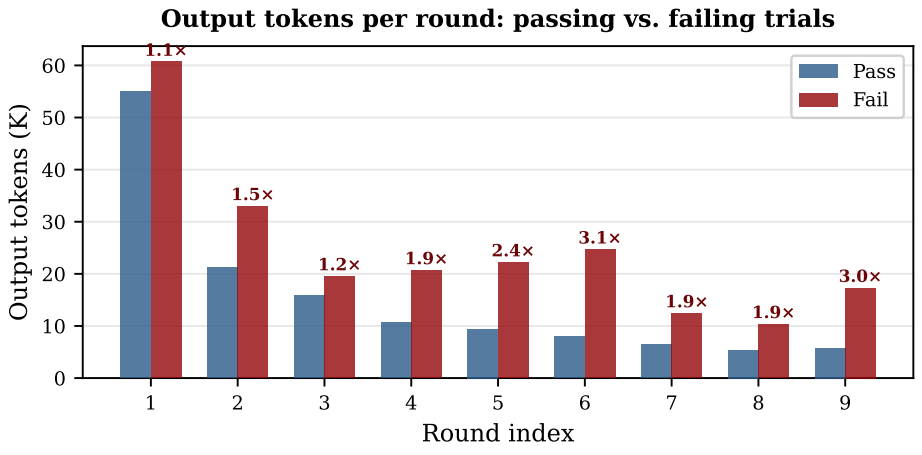
Failing Rounds Consume More Tokens
At the same round index, failed trials usually produce more output tokens than passing trials. Across rounds 1-9, failing trials emit 1.1x to 3.1x as many generated tokens as passing trials at the same depth. This is a diagnostic association rather than a causal claim.