SWE-Vision: A Minimal Agent for Advancing Visual Intelligence
2026-03-09
Test Time Scaling for Visual Understanding
via Interactive Coding and Observing
GitHub
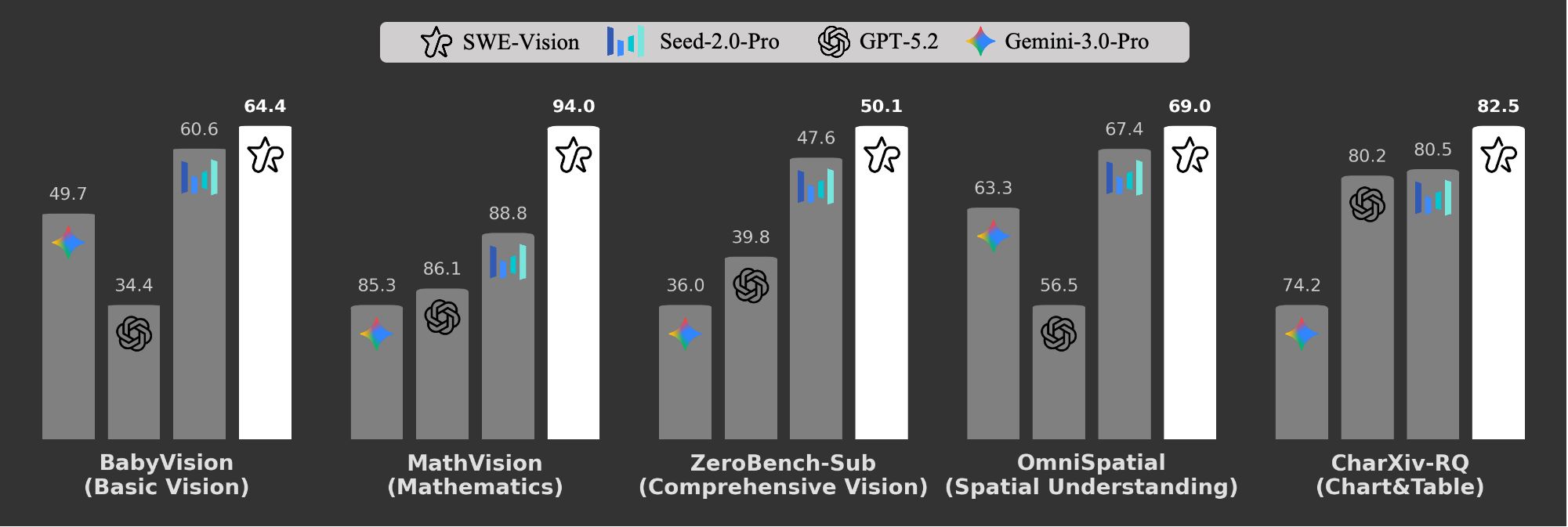
SWE-Vision is a multimodal agentic workflow. For BabyVision, ZeroBench-Sub and OmniSpatial, we report the result of SWE-Vision with Seed-2.0-Pro. For CharXiv and MathVision, we report the result of SWE-Vision with GPT-5.2. All tested models are in thinking mode with highest thinking budget.
Introduction
Visual understanding and coding are two core capabilities of frontier multimodal large language models — yet they exhibit strikingly different performance comparing to human ability. In coding, modern models already operate far beyond expert human levels, capable of generating, debugging, and optimizing complex projects. In vision, however, the gap remains substantial: models still struggle with tasks that humans solve effortlessly, as our previous project BabyVision shows. This asymmetry suggests a natural question: can coding be used to improve vision?
Many subsequent efforts have followed the “thinking with images” paradigm introduced by OpenAI, incorporating toolchains to enhance visual understanding. In practice, however, the gains have been modest. These systems often rely on manually engineered tools and are narrowly optimized for specific benchmarks—such as high-resolution image understanding—leading to two major limitations: (1) the manually designed tools are unfamiliar to the base model, burdening effective learning and exploration especially for RL; and (2) the evaluations are limited in scope, making it difficult to assess true generalization. As a result, the community still lacks a clean, open-source framework that enables models to improve visual capabilities in a broadly generalizable way.
This is the core idea behind SWE-Vision — an agentic loop that equips vision-language models with a simple, stateful environment, enabling them to write and execute Python code to reason about visual inputs. Rather than relying solely on internal visual representations or ad hoc tools, SWE-Vision allows the model to program its way to the answer: loading images with PIL, performing pixel-level analysis with NumPy, generating visualizations with matplotlib and different libraries, and seamlessly integrating these computational tools with the base model’s native visual understanding and multi-turn coding ability.
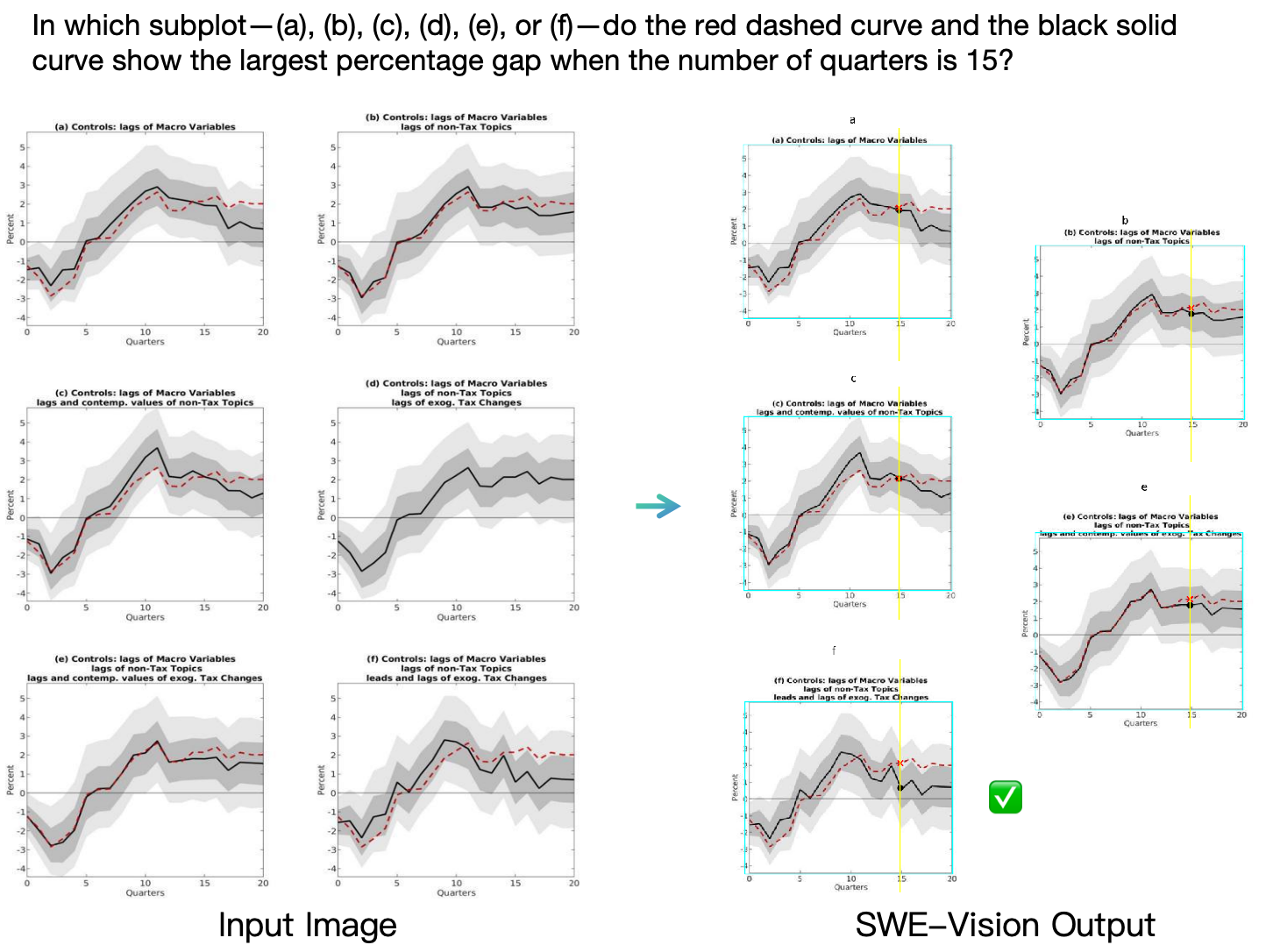
Case study of SWE-Vision (GPT-5.2-xhigh) solving a visual task. We ask the model to determine which subplot has the largest gap between the red dashed curve and the black solid curve at Quarters = 15. The SWE-Vision agent solves this rigorously by first excluding subplot (d), then locating the two curves at Quarters = 15 in each candidate subplot and using executable code to measure the gap precisely. This structured and verifiable process is much more reliable and interpretable than the direct “eyeballing” approach commonly used by conventional vision-language models.
The benchmark results are also striking. Across five diverse vision benchmarks — spanning foundational perception, chart reasoning, mathematical problem solving, spatial understanding, and complex multi-step visual challenges — SWE-Vision consistently improves the frontier LLM such as GPT-5.2-xhigh and Seed-2.0-Pro and achieves state-of-the-art results: 64.4 on BabyVision, 94.0 on MathVision, 50.1 on Zero-Bench-Sub, 69.0 on OmniSpatial, and 82.5 on CharXiv-RQ.
The experimental results show that including a general coding tool is a meaningful test-time scaling direction to improve the performance of the frontier LLM on vision tasks. However, we also find that the relative performance gain are to different base models, related to the function calling, coding and long-context ability of the base model. To fully unlock the potential of agentic visual understanding with SWE-Vision, we need more comprehensive training with deeply interleaved visual-and-coding SFT and RL data — enabling models not just to use tools, but to natively integrate perception and programmatic reasoning.
Cases: Visual Test Time Scaling with Coding
Below we show some trajectories of SWE-Vision solving visual tasks. Each trajectory illustrates the full agentic loop: the model receives an image, reasons about it, writes Python code, inspects the results, and iterates until it reaches an answer.
SWE-Vision: System Design
Why Give LLMs Code Execution?
The key insight is that many visual reasoning failures are not failures of seeing but of processing. When a model looks at a chart and estimates "about 75%", it may have perceived the bar heights correctly but failed to compute the precise ratio. When it counts objects in a cluttered scene, it may see each object but lose track of the tally. These are exactly the kinds of errors that a few lines of Python can eliminate.
SWE-Vision is designed around a simple principle: let the model decide when and how to use code. The model is not forced to write code for every question — it retains the option to answer directly when confident. But when the task benefits from precise computation, pixel-level analysis, or iterative exploration, the model can reach for its Jupyter notebook and work through the problem systematically.
Architecture Overview
SWE-Vision follows an agentic loop architecture with two core tools, execute_code and finish:
User Query (+ images)
│
▼
┌──────────────────────┐
│ LLM (e.g. GPT-5.2) │◄───────────────────────┐
│ │ │
│ Tool Calls: │ │
│ ┌────────────────┐ │ ┌──────────────┐ │
│ │ execute_code │─┼────►│Jupyter Kernel│ │
│ └────────────────┘ │ │ (Docker) │ │
│ ┌────────────────┐ │ └──────┬───────┘ │
│ │ finish │─┼──► Answer │ (Output) │
│ └────────────────┘ │ │ │
└──────────────────────┘ text + images ──────┘
The workflow proceeds as follows:
-
User Input. The user provides a query along with one or more images. The images are both (a) passed to the LLM as visual content in the conversation and (b) copied into a shared filesystem accessible to the Jupyter kernel.
-
Reasoning & Tool Selection. The LLM receives the query and images, reasons about the task, and decides whether to answer directly or invoke the
execute_codetool to run Python code. -
Code Execution. When the model calls
execute_code, the provided Python code is executed in a persistent Jupyter kernel running inside a Docker container. The kernel retains all state — variables, imports, loaded data — across multiple calls, enabling multi-step analyses. -
Result Feedback. The execution results — including text output (stdout), error messages, and any generated images (e.g., matplotlib plots) — are fed back to the LLM as part of the ongoing conversation. Generated images are captured and returned as visual content, so the model can inspect its own plots and intermediate visualizations.
-
Iteration. The model examines the results, decides if more computation is needed, and either calls
execute_codeagain or calls thefinishtool with the final answer.
Key Design Decisions
Stateful Jupyter Kernel. Unlike stateless code execution, a persistent Jupyter kernel lets the agent build up context over multiple tool calls. The model can load an image in one call, inspect its properties, apply transformations in the next call, and compute a final answer in a third — all without reloading data or re-importing libraries. This mirrors how a human data scientist would work in a notebook.
Docker Sandboxing. All code runs inside an isolated Docker container with a controlled package environment (NumPy, Pandas, OpenCV, PIL, scikit-image, matplotlib, and more). A shared volume mount (/mnt/data/) enables file exchange between the host and the kernel. This provides both security (arbitrary code execution is sandboxed) and reproducibility (the environment is consistent across runs).
Image-In / Image-Out. SWE-Vision supports bidirectional image flow. User images are passed to the LLM and placed in the kernel's filesystem. Images generated by the kernel (e.g., annotated images, plots, heatmaps) are captured and returned to the LLM as visual content. This creates a powerful feedback loop: the model can generate a visualization to verify its own reasoning, inspect edge detection results, or overlay annotations on the original image.
OpenAI Function Calling Interface. SWE-Vision uses the standard OpenAI function calling (tool use) API, making it compatible with any OpenAI-compatible endpoint. The two tools — execute_code and finish — are defined as structured function schemas. This means SWE-Vision works out of the box with OpenAI models, but also with other providers through OpenAI-compatible APIs.
System Prompt Design
The system prompt instructs the model to behave as an expert assistant with notebook access. Key elements include:
- Explicit documentation of the file system layout (
/mnt/data/) - Guidance to use
print()for text output andplt.show()for plot capture - Encouragement to work step-by-step and examine intermediate results
- Permission to call
execute_codemultiple times for iterative exploration - Instructions to call
finishonly when confident in the answer
This prompt design is intentionally minimal — it tells the model what tools are available and how to use them, but does not prescribe when to use code or what algorithms to apply. The model's own reasoning capabilities determine the problem-solving strategy.
Experiments
Benchmarks
We evaluate SWE-Vision across five diverse vision benchmarks, chosen to cover a broad spectrum of visual reasoning capabilities:
| Benchmark | Category | Description |
|---|---|---|
| BabyVision | Basic Vision | Fundamental perceptual tasks: Fine-grained Discrimination, Visual Tracking, Spatial Perception, Visual Pattern Recognition |
| CharXiv-RQ | Charts & Tables | Reasoning questions over real-world academic charts from arXiv papers |
| MathVision | Mathematics | Mathematical problem solving from visual figures, diagrams, and plots |
| OmniSpatial | 2D & 3D Spatial | Spatial reasoning tasks including distance estimation, object arrangement, and dynamic reasoning in both 2D and 3D scenes |
| ZeroBench-Sub | Comprehensive Vision | Multi-step, multi-skill visual questions requiring fine-grained perception and complex reasoning |
Setup
- Model under test: Gemini-3-Pro (high), GPT-5.2 (xhigh), Seed-2.0-Pro (high).
- SWE-Vision configuration: GPT-5.2/Seed-2.0-Pro with max reasoning effort, max 100 agent iterations per task.
- Judge model: GPT-5 as LLM-as-judge for answer correctness evaluation.
Results
Analysis
Consistent improvement across both models and all benchmarks. SWE-Vision improves over base models on every benchmark tested. With GPT-5.2, gains range from +2.3 to +18.2 points; with Seed-2.0-Pro, gains range from +1.6 to +3.8 points. This consistency across two fundamentally different model families confirms that code execution is a broadly useful capability for visual reasoning, not an artifact of any single model's weaknesses.
Largest gains on perceptual tasks. The most dramatic improvement is on BabyVision with GPT-5.2 (+18.2 points, 34.4 → 52.6), which tests basic visual perception — counting, color recognition, and spatial relationships. These are precisely the tasks where code-based analysis (e.g., pixel counting, color histogramming, contour detection) can most directly compensate for the model's visual limitations. Seed-2.0-Pro also sees a meaningful +3.8 point gain on BabyVision (60.6 → 64.4), though the smaller delta reflects its stronger baseline perception.
Strong mathematical reasoning gains. MathVision sees the second-largest improvement with GPT-5.2 (+7.9, 86.1 → 94.0), reflecting the model's ability to extract data from visual figures and compute answers programmatically rather than estimating. Even Seed-2.0-Pro, which already scores 88.8, is pushed to 90.7 (+1.9) — demonstrating that code execution continues to help even near the performance ceiling.
Spatial and comprehensive reasoning. OmniSpatial (+4.7 for GPT-5.2, +1.6 for Seed-2.0-Pro) and ZeroBench-Sub (+3.9 for GPT-5.2, +2.5 for Seed-2.0-Pro) both see meaningful improvements. Spatial reasoning benefits from the model's ability to measure pixel distances and compute geometric relationships. ZeroBench-Sub, which requires multi-step reasoning across multiple visual skills, benefits from the iterative nature of the notebook — the agent can decompose complex questions into sequential analysis steps.
Stronger coding models benefit more. A striking pattern emerges from the dual-model evaluation: GPT-5.2, which has stronger code generation capabilities, consistently sees larger absolute gains from SWE-Vision than Seed-2.0-Pro across all five benchmarks. This is most evident on BabyVision (+18.2 vs +3.8) and MathVision (+7.9 vs +1.9). The result makes intuitive sense — SWE-Vision's power comes from writing and executing code, so a model that produces more correct, targeted programs will extract more value from the framework. This suggests that investing in a model's coding proficiency yields compounding returns: not only does the model become a better programmer, it also becomes a better visual reasoner when paired with tool-augmented pipelines like SWE-Vision.
Discussions
Several limitations merit discussion:
- Dependence on the base model's visual reasoning and coding ability. SWE-Vision's effectiveness is bounded by the LLM's ability to write correct, relevant code and analyze the results correctly. The gap between GPT-5.2 and Seed-2.0-Pro gains may partly reflect differences in coding proficiency, not just visual capability. If the model writes buggy code or chooses inappropriate algorithms, the tool may not help or could even hurt performance.
- Failure modes. We observe cases where the agent enters unproductive loops — repeatedly trying similar approaches that fail, or generating overly complex code for simple tasks. The maximum iteration limit provides a safety net, but these cases still consume resources without producing better answers.
- Errors Introduced by Code. Programmatic analysis does not always outperform pure LLM visual reasoning. In some cases, writing and executing code to analyze an image can introduce new errors—whether from flawed assumptions, incorrect implementations, or misinterpretation of intermediate results. Therefore, the agent must not only execute code, but also critically evaluate its outputs, revise faulty logic when necessary, and dynamically reflect whether coding is beneficial for a given problem. Below, we present an interesting failure case from our experiments that illustrates this challenge.

An error case from SWE-Vision (GPT-5.2) illustrates this issue clearly. The task is to count the number of dogs with visible shadows in an image. The agent makes a seemingly clever decision: instead of directly counting shadows, it attempts to count the dogs by detecting their noses as proxies. However, due to the image-processing code, the system incorrectly detects nine noses. This flawed intermediate result propagates through the reasoning chain and ultimately leads to an incorrect final answer of nine.
Future Directions
The success of SWE-Vision across multiple model backends points to several promising research directions:
- Richer tool libraries. Beyond a general-purpose Python notebook, specialized tools — 3D rendering engines, physics simulators, OCR systems, symbolic math solvers, even CLI and GUI tools — could further expand the model's capabilities, particularly in areas where current gains are smaller.
- Learning when to use tools. Currently, the model decides when to use code based on its general reasoning capabilities. Fine-tuning with high-quality human demonstrations or reinforcement learning could optimize this decision, reducing unnecessary code execution on tasks where the base model is already strong.
- Reflecting on the code execution. The agent must not only execute code, but also critically evaluate its outputs, revise faulty logic when necessary, and dynamically reflect whether coding is beneficial for a given problem.
- More modalities. The current image-in/image-out design could be extended to support audio, video, and interactive visualizations, enabling richer feedback loops.
- Model-adaptive strategies. Given the finding that the benefit varies across different tasks, future work could explore adaptive execution strategies that allocate more compute budget to tasks where the base model is likely to struggle.
- Visual agentic data engineering and training. Unlike traditional data used to train multimodal LLMs, which are basically
Conclusion
SWE-Vision demonstrates that vision-language models can substantially enhance their visual reasoning by learning to write code about what they see. By embedding a stateful Jupyter notebook within an agentic loop, we allow models to compensate for perceptual limitations through precise, programmatic analysis. The framework is model-agnostic, benchmark-general, and delivers consistent performance gains across all evaluated tasks.
More broadly, this suggests that test-time scaling at the frontier of multimodal AI may not hinge on simply enabling models to see better by allocating more text tokens. Instead, the key may lie in enabling models to think and act more effectively with the vision they already possess and a richer multimodal context.
Citation
If you find it useful in your research, please kindly cite:
@misc{unipat2026swevision,
title = {SWE-Vision: A Minimal Agent for Advancing Visual Intelligence},
author = {Liang Chen and Haozhe Zhao and Tianyi Ma and Kuan Li},
year = {2026},
url = {https://unipat.ai/blog/SWE-Vision},
}